游记可以扔掉了,多维度摸清陌生城市的一套七层方法(v2.1)
下个月要去一座没去过的城市,你会怎么准备?
大概率是这样:刷十几条小红书,问一个在那边待过的朋友,再翻一篇"避坑指南"。半小时后,你感觉自己大致摸清了,哪里好玩、哪里宰客、人怎么样,心里都有了数。
这种感觉很可靠,也很危险。你看到的那座城市,是别人替你筛过的版本。小红书给你滤镜,朋友给你他那个阶层的体感,避坑指南挑最耸动的几个点讲给你听。信息越堆越多,"我懂了"的错觉就越强。
摸清一个陌生地方,难点不在信息够不够,在你有没有一套拆信息的框架。
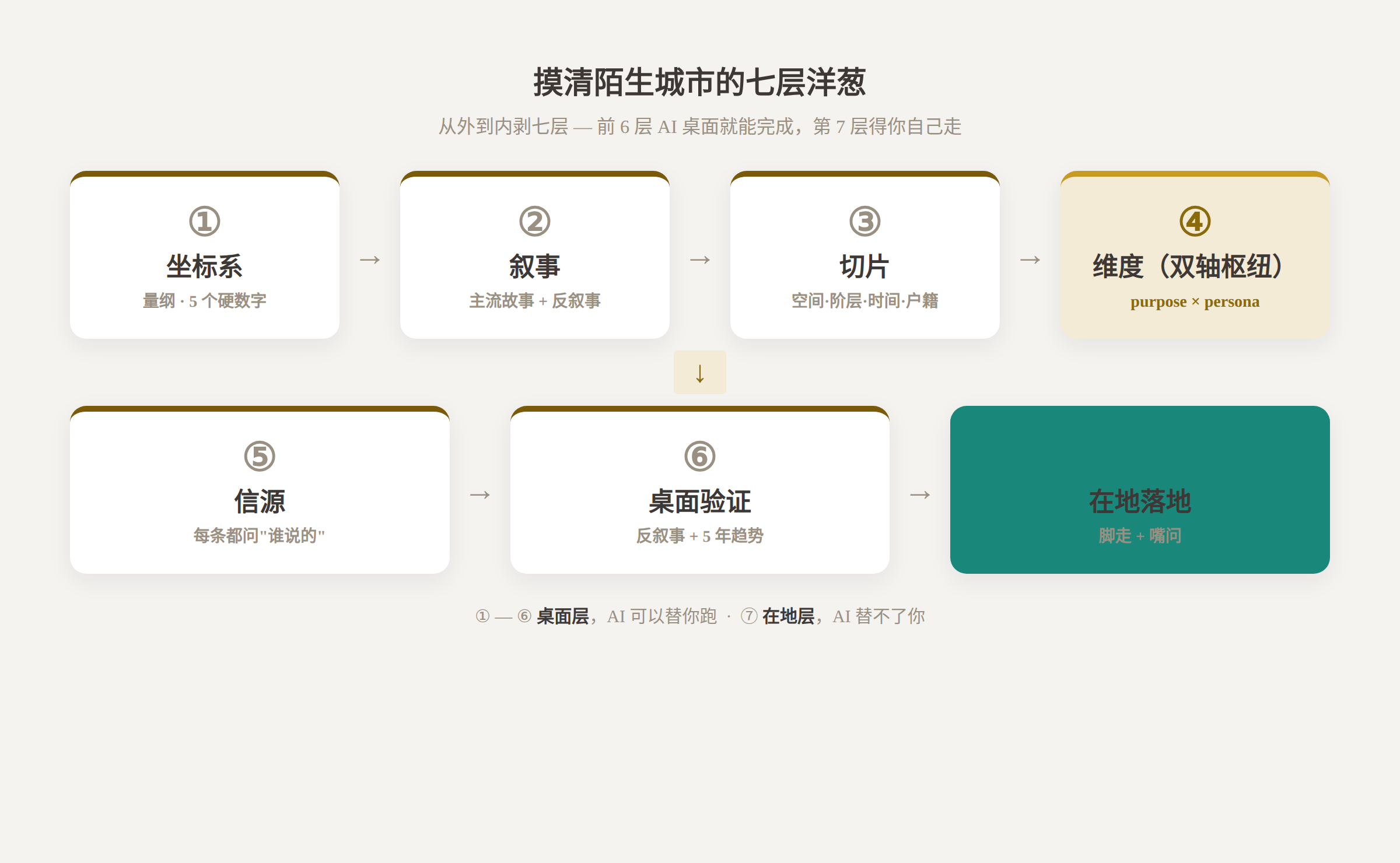
我自己用的是一套七层的框架,像剥洋葱一样从外往里剥。前六层在桌面上就能完成,第七层得你自己用脚走、用嘴问。下面我拿它当场拆一遍上海,一个你以为很熟、其实多半只熟悉它叙事的城市。
先建量纲,不然你看到的都是浮的
第一层叫坐标系。在了解任何细节之前,先给这座城市建一个量纲,也就是几个能记住的硬数字,配一句话定位。
上海的量纲可以压成五个数:常住人口约 2480 万,2024 年 GDP 约 5.39 万亿元,人均 GDP 约 3 万美元,中国跟北京并列的顶级直辖市,1843 年开埠。
这五个数一摆,你对上海的判断就有了锚。之后再听到任何关于它的说法,你都能掂量一下。有人说"上海遍地是钱",你拿人均 3 万美元一比,这是中等发达经济体的水平,可它是个平均数,而平均数最会骗人。这个疑问会带你往下走。
第二层叫叙事,把这堆数字串成一个故事。一座城市没有故事,就只是一摞统计年鉴。
上海的故事是开埠开出来的。1843 年它还是长江口一个县城,靠着租界和通商口岸,几十年里长成远东第一大都市,外滩的银行和百乐门的舞曲撑起了"东方巴黎"。1949 年之后它被收编成工业基地,利税上缴中央,繁华冻结了近四十年。第二次起飞要等到 1990 年浦东开发,陆家嘴从一片农田变成今天那条天际线。
今天上海的主流叙事是"中国最国际化、最精致、最讲规则的城市"。请记住这句话,等会儿我们要拿它当靶子。
这就是第一条心法:先建量纲,再填细节。量纲不出来,后面所有信息都是浮的。而人均 3 万美元这个平均数,已经悄悄埋下了这座城市分成两个世界的线索。
一个城市内部从来不是均质的
第三层叫切片,专门用来对付一个很常见的错觉:在市中心住了三天,就以为懂了这座城。
一座几千万人的城市,内部差异比城市与城市之间还大。至少要切四刀。
空间上切一刀。浦西的黄浦、静安、徐汇是老钱和精致中产的地盘,二手房一平米十几万;浦东的张江挤满写代码的工程师;而真正让这座城市运转起来的快递员、服务员、建筑工,住在通勤一个半小时开外的外环和城乡结合部。
阶层上再切一刀。本地有房的拆迁户、外企的海归高管、租房攒钱的白领沪漂、撑起日常的蓝领外来工,活在同一个上海,过的是四种上海。把他们分开的那条隐形的线,叫户籍。
时间上还能切一刀。十月十一月的上海最舒服,六月的梅雨和盛夏的桑拿天最难熬,春节一到,几百万外来人口返乡,这座城市会短暂地空下来。你哪个时候去,看到的是不同的上海。
第二条心法:故事加切片,比数据本身重要。数据告诉你这座城市"是什么",故事告诉你"为什么是这样",切片告诉你"它对谁是这样"。说"上海人均 3 万美元"没错,可对一个住在外环、每天通勤三小时的人,这个数字没多大意义。
同一座城市,你为什么去 × 你是哪一型
走到这里,你对上海已经有了不少判断。但桌面上看到的所有信息,对你这个具体的人到底有多大用,要看两件事:你为什么去,你是哪一型。这是第四层。
第一个问题:你为什么去。
出差三天的人和打算搬过去的人,要看的东西几乎不重合。出差的人得弄清见客户穿什么、饭桌上哪些话不要碰、打车用哪个软件;打算搬过去的人对这些没什么兴趣,真正要命的是能不能落户、孩子将来上学怎么办、那套房子该咬牙买在内环还是退到外环。同一座城市,问错了问题,约等于没了解。
第二个问题:你是哪一型。
这个比"为什么去"更隐蔽,但同样重要。
同样是打算搬到上海,"职业发展型"该锁定张江、徐汇滨江这些产业集中区,关心薪资水平、跳槽机会、行业活动密度;"品质生活型"该看三甲医院分布、菜场质量、空气和绿地,瞄准的是徐汇内环、长宁古北那种生活舒服的老社区;"文化探索型"该跳过外滩和迪士尼,去逛安福路的独立书店、虹口的老弄堂、铜川路的水产市场,找那种"叙事里没有的上海";"家庭型"得反过来死磕学区,闵行虹桥古北和浦东张江外区的学区房均价能差两倍;"避险稳定型"则要算一笔长期账:上海生活成本对你的工资收入比是不是合理,户籍门槛会不会把孩子卡在中考。
一个问大盘,一个问坐标点。两个一组合,你要看的东西就能压缩到一张清单。这是第三条心法:你的关切是 purpose 和 persona 两个轴决定的,不是一个。
第三个问题更现实:你的钱够不够。前两个问题决定你看什么,第三个问题决定你能不能落地。每一型关心的成本项不同:职业型盯房租收入比和行业活动费用,品质生活型盯医疗 + 菜场 + 公共空间的成本,文化型盯月度文化消费,家庭型盯学费和儿科自费部分,稳定型盯月度总盘和通胀。出发前列一张四到六行的成本表,每行附"数值 + 信源 + 年份 + 跟你出发地的倍数对比",比读一百篇生活攻略管用。光看"上海人均 3 万美元"没用,得知道你的月开销在上海占你工资的多少。
每条信息都要问一句"这是谁说的"
桌面再往里一层,是第五层:信源标注。每一条关于这座城市的判断,你都得知道它是谁说的。政府统计公报、主流媒体报道、还是小红书上一个人随手一条吐槽,这三者的可信度差着好几个量级。
调研中国大陆城市的时候,信源生态特别丰富,但也特别容易被骗。
光是 UGC 平台就有八种各有偏向:知乎里"在 X 工作是怎样的体验"系列,高赞回答密度高但写作偏文艺;小红书搜"X 真实"出来的滤镜痕迹明显;豆瓣本地组里中产吐槽密度大但用户偏 25-40;B 站 vlog 评论区比视频本身有信息量;微博话题是突发事件的第一发酵地;微信公众号有不少软文;本地论坛(19 楼、东方网那种)保留着上一代中产视角;抖音算法茧房严重。
每个平台你都得知道它在哪个维度上扭曲。然后还要叠加一层:政府统计公报数据可靠但滞后 3-12 个月,主流媒体的"崛起 / 衰落"叙事二选一,本地党报正面密度极高。
给你看一个真实的反例,这也是整套方法里我觉得最值钱的地方。
调研上海的时候,我搜到一条在中文网络上传得很广的说法:"2024 年中国外资净流出 1684 亿美元,是 1990 年以来最大的资本外逃。"数字很吓人,也特别适合转发。我做的第一件事不是相信它,是去查它的源头。顺着链接扒下去,这条数字的唯一出处,是一家立场极端、长期不可靠的媒体。我再去比对官方和财经媒体的口径,上海 2024 年实际利用外资约 176 亿美元,比上一年降了约 27%。
这两件事差别巨大。"年度流入放缓 27%"是真的,"存量大规模外逃"是吓唬人的。少了第五层这一步,你就会把一条谣言当成判断上海的依据,还以为自己掌握了内幕。
第四条心法:信息源比信息本身重要。知道一条信息从哪儿来,决定了你是真懂,还是只是被人喂了一口。
主动找反叙事,别被光鲜数据骗
第六层叫桌面验证。前五层帮你建立认知,第六层负责防止这个认知被叙事牵着走。
最管用的一个动作,是主动去找反叙事。任何一座城市,官方和媒体都偏爱讲它的崛起故事,硬币的另一面得你自己翻。
还记得上海那句主流叙事吗,"最国际化的城市"。我们就拿它当靶子,去找反例。
第一个反例,外国人在用脚投票。据南华早报的统计,上海的外籍常住人口从 2018 年的约 20 万,掉到 2023 年的约 7.2 万,五年缩水约 64%。一座号称"最国际化"的城市,外国人少了将近三分之二。人会用脚投票,这种数字往往比任何宣传都诚实。
第二个反例,年轻人也在被分流。2025 年深圳常住人口增加了约 25.9 万,杭州增加约 7.6 万,而上海受落户门槛和生活成本所限,只微增约 5 万。
第三个反例在写字楼里。多家国际机构(仲量联行、世邦魏理仕)2024 年的报告都指出,上海甲级写字楼空置率连续多个季度走高,普遍在 20% 以上,租金同步下滑。"国际金融中心"光环背后,是租赁市场实打实的冷却 —— 这种细节,叙事层面看不到,得自己去翻。
这三个反例无意否定上海。它依然有一千多家跨国公司地区总部、累计超过三千七百亿美元的外资家底,两个机场 2024 年客流约 1.24 亿,反超了疫情前的高点。但把光鲜叙事和这些反例摆到一起,你眼里的上海才立体起来:一个机构存量还很厚、增量却正被邻居抢走的高位平台。
判断自己有没有被叙事带跑,有个特别简单的自查。你对这座城市说出来的话,赞美和批评各占多少?要是几乎全是好话,那基本可以断定你只收到了主流叙事,回去补反例。
第五条心法:没主动找反叙事,就是没做过验证。
跟反叙事配套的,是另一个动作:永远看 5 年走势,不只看单年数字。"上海 2024 年人均 GDP 3 万美元"是截面,"上海 5 年常住人口微增 5 万 vs 深圳 5 年净增 200 多万"才是趋势。截面告诉你它长什么样,趋势告诉你它正在变成什么 —— 前者好看,后者诚实。第六条心法:比 5 年走势,不比单年数字。
用脚走,张嘴问 ── AI 替不了你的最后一公里
到这里,桌面上能做的事情都做完了。第六层结束,AI 和搜索引擎能给你的,不会再多了。
但桌面认知和真实城市之间,永远隔着一层。你需要第七层:在地落地。这一层 AI 替不了你,因为它只能用你的脚和嘴去完成。
落地的事情分两块:用你的脚和眼,看到桌面看不到的;用你的嘴和耳,问到桌面问不出的。
先说脚和眼。
到了上海,第一天别急着去外滩。挑一条贯穿新旧城区的公交,比如 49 路,从首站坐到末站,中间不下车。看建筑怎么从老洋房变成动迁安置房再变成农民房;看上车的人怎么从西装白领,慢慢变成提着菜篮的退休阿姨,再变成挤在车厢后排的外来务工者。这一趟下来,你对上海的"中心"是什么意思,会有一个跟地图上完全不同的体感。
第二天找一个你不熟的核心片区,规划一段 3 公里的步行。盯着看四件事:商铺的空置率(一连五家关门是商圈在衰退),路人的步行速度(快是工作型,慢是休闲型或老龄化),垃圾分类投放点是真的有人执行还是装样子,还有沿街车辆的品牌密度。这四个细节加起来,告诉你的"治理水平"和"阶层底色",比所有公开报告都准。
剩下还有几样事要做满:找一个社区菜市场(不是商场超市),早 7 点去,看菜价、品类丰富度、摊主口音;找一家便利店,买瓶水,看货架上进口、全国连锁、本地品牌的占比;早高峰挤一次地铁 2 号线,从远郊站坐到陆家嘴,看人怎么从衣着普通的通勤族慢慢被替换成西装革履;下午 4 点去一个老牌公园,看跳舞的退休群体里有多少是上海口音,多少是带孙子的"老漂"。
这六件事用不到一天,但它们打开的信息维度,是 AI 桌面调研无论多详尽都打不开的。
再说嘴和耳。
最便宜、最有效的真人采访,是出租车司机。每天他们要载几十个不同阶层的人,没人际包袱,也敢说真话。每打一次车,问这五句话,2-3 分钟车程能问完:
- • 师傅,这边物价怎么样?吃顿饭、租房一般什么价?
- • 治安行不行?哪个区少去?
- • 现在年轻人都往哪儿跑?是留下还是出去?
- • 这阵子本地最大的事是啥?
- • 您是本地人还是外地来的?外地的话,这地方对外地人友好吗?
一周打三五次车,把不同司机的回答放一起看。如果三个司机方向一致,那是城市共识;如果分歧大,说明这件事在切片之间体感不同。这是所有真人采访工具里 ROI 最高的。装作只是闲聊,别拿小本本记,也别开"我在做调研"的开场白,否则司机会立刻进入对外宾说官话的模式。
除了司机,还有几条线索得问:酒店前台或房东问"这街区夜里安全吗、楼下便利度、这边住的主要是什么人";第一个本地朋友或同事问"哪些话题不要主动提、30 岁的人下班后干嘛、近 5 年最大的变化和困境";如果是出差,多问一句客户公司 HR "他们的接待习惯、礼物送什么不送什么"。
第七条心法:AI 给你框架,第七层得你自己用脚和嘴完成。承认这一点,是这套方法诚实的地方。

一段诚实交代
写到这里得插一句。这篇文章里出现的上海具体数字 —— 5.39 万亿、2480 万、外籍 7.2 万、年降 27%、空置率 20%+ —— 大头来自我自己跑的 city-profile brief。量级和趋势方向我相信是对的,错三五个百分点不致命,但精确数字我没在写作 session 里逐条二次核。如果你打算拿这些做决策(投资、移居、出差),自己再核一遍 —— 这其实也是第七层在地落地的另一面:AI 给的精确数字,永远要打一道折看。
写在最后
七层走完,你心里那座城市,才算你自己一层层拆出来的。
回头看一眼这条路径:先建量纲,给它几个硬数字;用故事把数字串成线,再用切片告诉自己它对谁是这样;想清楚自己为什么去、是哪一型、钱够不够;每条信息都问一句这是谁说的;主动找一圈反叙事,比的是 5 年走势而不是单年数字;最后用脚走一遍、张嘴问几句。
前六层每层都很重要,但真正让"我懂这座城市"从一句话变成一种判断力的,是第七层。一份再漂亮的 AI brief,结尾都该附一张"还得自己去看、自己去问"的清单。这件事,平台和熟人替不了你。
想自己跑一遍这套方法
我把整套 city-profile skill(v2.1 完整版)打包上线了,丢进自己的 agent 就能跑 ── 下载地址见文末参考资料。
包里有完整的七层框架定义、purpose × persona 双轴模板、cn-mainland / global-en 双区域工具栈、POI 库(带 confidence 标签)、Hanoi 出差完整示例,以及自动复盘 + meta-retro 机制。中英双语入口,用法见 zip 里的 README.md 和 USAGE.md。
要是你拿这套方法拆了你接下来要去的城市,欢迎回来告诉我,你拆到了第几层,又在哪一层卡住了。
参考资料
\[1] 完整 skill 包下载:https://transorb.cc/files/city-profile-skill.zip
— 内含 SKILL.md + SKILL.en.md + USAGE.md + 七层 framework + persona/purpose presets + toolkits(cn-mainland / global-en)+ field-actions + POI 库 + Hanoi 示例。约 90 KB,28 个文件。